Méthodologie
Objectif
En moyenne, chaque état reçoit plus de 70 recommandations par année de la part de tous les mécanismes de supervision des droits de l’homme de l ONU. Avec 193 états membres de l’ONU, seul l’EPU a généré plus de 110,000 recommandations depuis 2007. Pour mettre en œuvre ces recommandations de manière efficace et systématique, leur catégorisation par thème est nécessaire.
A la suite de l’adoption du Programme de développement durable à l’horizon 2030, il y a un intérêt croissant dans les liens entre les recommandations en matière de droits de l’homme et les Objectifs de développement durable (ODD) et leurs cibles. Cependant, même si les catégories existantes de droits donnent des orientations sur ces liens, elles ne correspondent pas exactement aux objectifs et aux cibles des ODD. Jusqu’à présent, cette catégorisation a été faite par la main. Donne le numéro de recommandations disponibles, leur catégorisation par la main devient infaisable.
L’Institut danois pour les droits de l’homme (IDDH) a donc développé et formé un algorithme d'exploration de texte pour faire la connexion entre les recommandations relatives aux droits de l’homme et les ODD. Ce travail a été fait en collaboration avec Specialisterne – une entreprise sociale.
You can watch a presentation of Special Consultant Niels Jørgen Kjær explaining the methodology here.
L’ensemble des données
L’ensemble des données comprend toutes les recommandations de la part des organes de traites, des procédures spéciales du Conseil des droits de l’homme et l’EPU disponibles. Il a été crée en combinant des éléments de l’Index universel des droits de l’homme (qui est géré par l’Haut-Commissariat aux Nations unies aux droits de l’homme) et de la « Database of Recommendations “ géré par UPR Info. L’ensemble des données a été complémenté par l’IDDH ou nécessaire, et sera mis à jour périodiquement.
Métadonnées
Les “métadonnées” sont des données utilisées pour décrire ou pour catégoriser des autres données. Elles dons des “données sur les données”. Les métadonnées dans the SDG-Human Rights Data Explorer sont de deux types:
- Des propriétés descriptives qui donnent des informations sur, entre autres, le mécanisme de droits de l’homme qui a formulé une recommandation spécifique, ou le pays a lequel une recommandation a été adressée.
- Des catégories analytiques qui identifient les titulaires de droits adresses dans une recommandation spécifique, et l’objectif ou cible des ODD a lequel la recommandation est lié.
Les catégories analytiques sont décrites en plus de détail ci-dessus.
Titulaires de droits
The SDG-Human Rights Data Explorer identifie les titulaires de droits concernes par une recommandation spécifique. Les recommandations peuvent être liées à une catégorie de titulaires de droits, ou à plusieures, ou bien elles peuvent être liées a aucune catégorie. Les catégories de titulaires de droits identifiées dans the SDG-Human Rights Data Explorer sont les suivantes:
| Femmes et filles |
| Enfants |
| Peuples autochtones |
| Personnes handicapés |
| Migrants |
| Réfugiées et demandeurs d’asile |
| Personnes déplacées dans leur propre pays |
| Minorités ethniques et religieuses |
| Défenseurs de droits de l’homme |
| Lesbian, Gay, Bisexual, Transgender and Intersex (LGBTI) |
| Personnes agées |
| Jeunesse |
Catégories liées aux ODD
The 169 targets under the 17 Sustainable Development Goals serve as categories for the classification of the recommendations. The current data material reflects about 70 of the 169 targets. Recommendations are linked directly at the target level, with no residual categories at the Goal-level. This means that recommendations are only classified if they are linked to a specific target under one of the 17 Goals.
Une liste de toutes les cibles des ODD, et les liens entre ces cibles et des dispositions spécifiques des instruments de droits de l’homme et de normes internationales de travail se trouve ici : http://sdg.humanrights.dk/fr/goals-and-targets
L’analyse
Les recommandations relatives aux droits de l’homme ont été catégorisées en utilisant un processus d’analyse basé sur un apprentissage automatique semi-supervisé. A travers ce processus un algorithme a été forme pour faire la classification des recommandations de l’EPU, sur la base d’une sélection des exemples pour la formation (classifies par un expert humain), et une grande quantité des données qui n’étaient pas classifiées.
Afin de pouvoir préparer l’analyse pour l’apprentissage automatique, une sélection initial d’exemples a été identifiée par un expert humain pour chacune des 169 cibles des ODD, ou possible. Cette selection d’exemples est requise pour constituer une base sur laquelle l’algorithme puisse opérer (soi-disant “vérité terrain“). Afin de pouvoir identifier les exemples pertinents, l’expert humain a utilise des citations et des terminologies qui sont souvent utilises pour identifier des textes pertinents aux droits lies aux cibles spécifiques des ODD. Par exemple, des termes de recherches comme “violences contre les femmes” et “traite des femmes” ont été utilises pour identifier les exemples pour utiliser comme base de formation lies a la cible 5.2 qui vise a éliminer de la vie publique et de la vie privée toutes les formes de violence faite aux femmes et aux filles, y compris la traite et l’exploitation sexuelle et d’autres types d’exploitation.
Suite a cette identification d’exemples de ‘formation’, l’analyse l’apprentissage automatique a été mise en œuvre en 2 étapes :
Dans une première étape, l’algorithme de classification a été utilisé pour identifier des recommandations similaires aux exemples de formation dans chaque catégorie. Cette identification a été basée sur les métadonnées existantes – notamment les classifications thématiques dans les bases des données existantes de l’HCDH et UPR Info. Ces deux bases des données catégorisent les recommandations par des mots clés qui décrivent des groups de titulaires de droits ainsi que des dizaines de questions/thèmes de droits de l’homme auxquels les recommandations se réfèrent souvent. Dans l’ensemble des données, tous les mots clés ont été collectés. The algorithm was then used to identify patterns and correlations with the SDG targets in the combination of keywords between training examples and unclassified data. Through human feedback, the precision of the algorithm was enhanced in the course of the process.
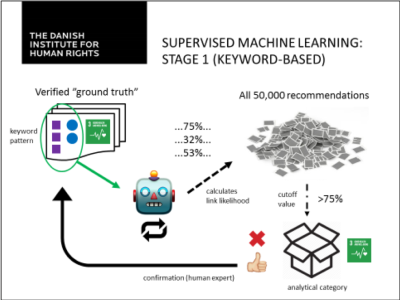
Dans le deuxième étape, l’algorithme a été formé pour analyser des textes directement afin de pouvoir identifier les liens avec les ODD – au lieu de compter sur les métadonnées. Cette étape a amélioré le niveau de précision, et a servi pour éliminer le besoin d’analyse par un expert humain. L’analyse du texte se base sur un « dictionnaire expert », construit sur la base de ‘vérité terrain’ déjà identifiée. Le dictionnaire expert collecte des expressions et des terminologies qui sont typiques pour une catégorie d’analyse spécifique, et ensuite, les attribue d’un ‘poids’. Avec une combinaison d’un dictionnaire ‘standard’ et les donnes émanant de sa formation, algorithme déterminé les valeurs de probabilité pour toutes les catégories existantes d’analyse pour toutes les recommandations dans l’échantillon. A travers le suivi et des modifications per l’expert humain, supplémentaire vérité terrain est identifié pour chaque catégorie. Ces exemples supplémentaires de formation sont utilisés pour mettre a jour la dictionnaire expert en continuation.
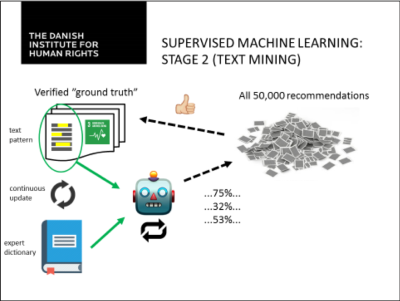
Depuis son développement, l’algorithme a été utilisé pour l’analyse et la catégorisation des recommandations des organes de supervision des droits de l’homme a part l’EPU, y compris les organes de traits et les procédures spéciales du Conseil des droits de l’homme. Ceci a servi pour agrandir le numéro de recommandations dans la base des données de 55,000 a plus de 200,000. Le fonctionnement de l’analyse est optimisé et élargi en continue.
Dernière mise a jour: 18-03-2024