Методология
Цель
В среднем каждый год государства получают более 70 рекомендаций в рамках различных механизмов ООН по мониторингу прав человека. Только в рамках Универсального периодического обзора (УПО) с момента начала работы этого механизма в 2007 г. было выработано более 110 000 рекомендаций для 193 государств-членов ООН. Для того чтобы государства могли систематически и эффективно реализовывать эти рекомендации, необходимо разделить их на тематические группы.
После принятия Повестки дня в области устойчивого развития на период до 2030 года возрос интерес к увязке рекомендаций по правам человека с Целями и задачами в области устойчивого развития (ЦУР). И хотя существующие тематические категории дают определенные подсказки, они не совсем точно соответствуют целям и задачам. Кроме того, до сих пор эта категоризация в основном выполнялась вручную. Учитывая огромное количество существующих рекомендаций и тех, что будут приняты в будущем, задача разбивки их на категории с привязкой каждой к тем или иным ЦУР выглядит просто обескураживающе.
Поэтому Датский институт по правам человека (ДИПЧ) в сотрудничестве с социальным предприятием Specialisterne (Специалисты) приступил к разработке и обучению алгоритма автоматической классификации рекомендаций органов ООН, занимающихся мониторингом соблюдения прав человека.
You can watch a presentation of Special Consultant Niels Jørgen Kjær explaining the methodology here.
Массив данных
Массив данных включает все имеющиеся рекомендации Договорных органов ООН, Специальных процедур Совета по правам человека и Универсального периодического обзора. Массив был создан как компиляция выдержек из массивов данных, содержащихся в базе данных Универсального указателя по правам человека, которая находится в ведении Управления Верховного комиссара ООН по правам человека, а также в Базе данных рекомендаций, которую ведет УПО Инфо (UPR Info). Датский институт по правам человека дополнил этот массив данных, где это необходимо, и будет периодически обновлять его в будущем.
Метаданные
"Метаданные" - это данные, служащие для описания или классификации других данных, т.е. - "данные о данных". В Поисковой системе ЦУР – права человека (SDG-Human Rights Data Explorer) содержатся метаданные двух следующих типов:
- Описательные свойства, информирующие, помимо прочего, о том, из какого механизма по правам человека исходит данная рекомендация и какой стране она адресована;
- Аналитические категории, которые определяют группы правообладателей, которым адресована данная рекомендация, и то, с какими ЦУР и задачами, связана данная рекомендация.
Аналитические категории более полно разъясняются ниже.
Категории групп правообладателей
Поисковая система ЦУР – права человека (SDG-Human Rights Data Explorer) определяет группу правообладателей, которым адресована данная рекомендация. Рекомендации могут быть не связаны ни с одной из групп правообладателей или могут быть связаны с одной или несколькими группами. В Поисковой системе ЦУР – права человека (SDG-Human Rights Data Explorer) установлены следующие категории правообладателей:
| Женщины и девочки |
| Дети |
| Коренные народы |
| Инвалиды |
| Мигранты |
| Беженцы и просители убежища |
| Внутренне перемещенные лица |
| Этические и религиозные меньшинства |
| Правозащитники |
| Лесбиянки, геи, бисексуалы, трансгендеры и интерсексуалы (ЛГБТИ) |
| Пожилые люди |
| Молодежь |
Категории целей в области устойчивого развития
169 задач в рамках 17 целей в области устойчивого развития служат категориями для классификации рекомендаций. Текущий объем материала отражает около 70 из 169 задач. Рекомендации напрямую связаны с задачами и не имеют каких-либо иных связей с целями. Это означает, что рекомендации подпадают под классификацию только в том случае, если они связаны с какой-то конкретной задачей в рамках одной из 17 целей.
Перечень всех задач Целей в области устойчивого развития и их связь с соответствующими документами по правам человека и международными трудовыми нормами можно найти здесь: http://sdg.humanrights.dk/ru/goals-and-targets
Аналитический процесс
Рекомендации по правам человека были разбиты на категории с помощью аналитического процесса, использующего машинное обучение с частичным привлечением учителя. Посредством этого процесса первоначально было проведено обучение алгоритма классифицированию рекомендаций УПО на основе небольшого набора обучающих примеров (классифицированных экспертом-человеком) и большого количества неклассифицированных данных.
Для подготовки к анализу на основе машинного обучения эксперт-человек определил, где это было возможно, первоначальный набор обучающих примеров для каждой из 169 задач Повестки дня на период до 2030 года. Этот набор обучающих примеров необходим для создания основы для работы алгоритма (так называемые "контрольные данные"). Чтобы установить подходящие обучающие примеры, эксперт-человек использовал общеупотребительные цитаты и термины, характеризующие определенный контент, связанный с правами человека, в рамках соответствующих задач ЦУР. Например, такие поисковые термины, как "насилие в отношении женщин" и "торговля женщинами", использовались с целью установления обучающих примеров для задачи 5.2, которая призывает к прекращению насилия в отношении женщин и девочек, включая торговлю людьми и другие виды эксплуатации.
Последующее проведение анализа на основе машинного обучения представляло собой двухэтапный процесс.
На первом этапе машинного обучения с учителем алгоритм классификации использовался для выявления рекомендаций, аналогичных обучающим примерам в каждой категории, на основе существующих аналитических метаданных, а именно тематических классификаций, содержащихся в существующих базах данных УВКПЧ и УПО Инфо (UPR Info). В обеих базах данных рекомендации разделены на категории, основанные на наборе ключевых слов, которые определяют ряд затрагиваемых групп, а также несколько десятков правозащитных вопросов, на которые обычно делаются ссылки в рекомендациях. В объединенном массиве данных, использованном для анализа, были собраны все существующие ключевые слова. Затем использовался алгоритм для определения комбинаций и корреляций с задачами ЦУР в сочетании ключевых слов между обучающими примерами и неклассифицированными данными. Благодаря контролю со стороны человека точность алгоритма в ходе этого процесса была повышена.
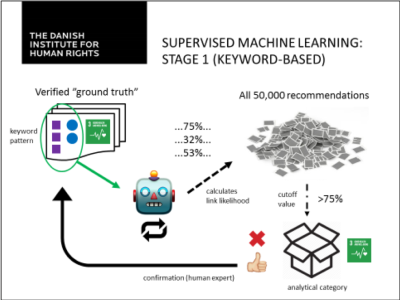
На втором этапе этот алгоритм был наделен возможностью анализировать текст непосредственно для определения наличия ссылок на ЦУР, вместо использования метаданных. Эта функция была добавлена, чтобы повысить точность и полностью исключить необходимость классификации человеком с расчетом на анализ данных в будущем. Анализ текста опирается на "экспертный словарь", который составлен человеком-экспертом на основе ранее установленных контрольных данных. В экспертном словаре собраны термины и выражения, характерные для данной аналитической категории, и им присвоен вес. В сочетании со стандартным словарем английского языка и данными обучения этот алгоритм затем определяет значения вероятности связи со всеми существующими аналитическими категориями для всех рекомендаций в выборке. Посредством контроля со стороны человека для каждой из категорий выявляются дополнительные контрольные данные. Эти дополнительные обучающие примеры используются для постоянного обновления экспертного словаря путем корректировки значений вероятности для терминов и выражений.
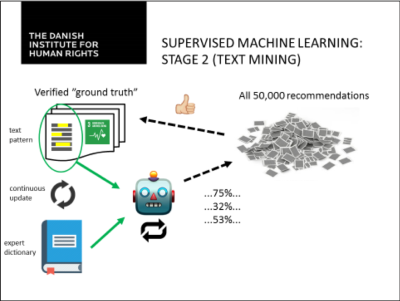
Впоследствии этот алгоритм был использован для анализа и классификации рекомендаций, полученных от органов мониторинга прав человека помимо УПО, а именно, Договорных органов, а также Специальных процедур Совета по правам человека. Это привело к расширению объема данных примерно с 55 000 рекомендаций УПО до более чем 200 000 рекомендаций и наблюдений различных органов вместе взятых. Средства анализа оптимизируются и расширяются на постоянной основе.
Последнее обновление: 18-03-2024